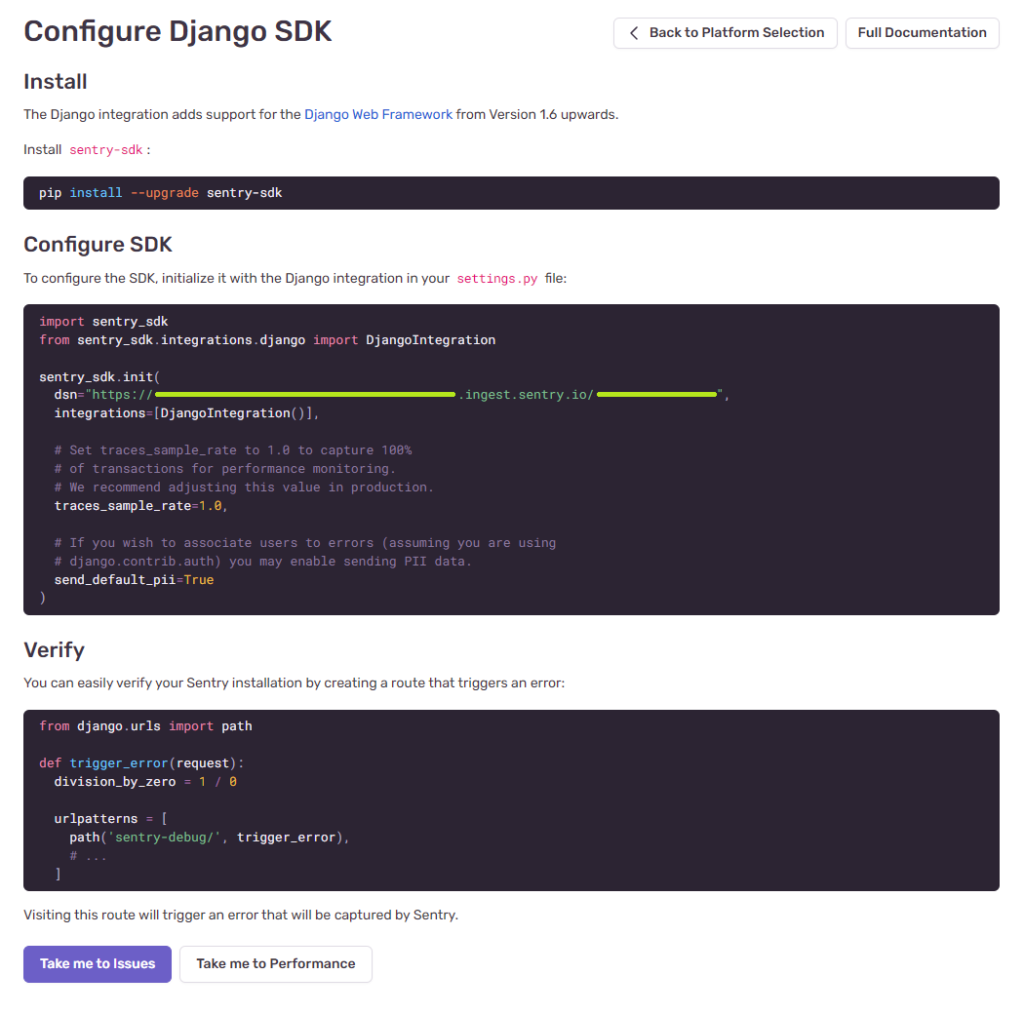
With the basics down, the next step in this little adventure w/ Javascript is to make it work in a React.js environment (Next.js to be more precise).
There were some iterations. What emerged was (using a Next.js framework):
app/models.ts— the model types (Card) I’m working with.app/cards/page.tsx— the component displaying the card “carousel” and a scroller.app/cards/ui/CardCarousel.tsx— component displaying the card “carousel.”app/cards/ui/cardcarousel.module.css— styling for theCardCarousel.app/cards/ui/Scroller.tsx— component displaying the scroller (I will omit this in the post since it’s not really relevant).app/lib/ui/renderers.tsx— a renderer function that renders aCard.
The hierarchy of files will differ from time to time and from person to person. What I consider the main trick to get this working with React.js is in the app/cards/ui/CardCarousel.tsx::Carousel
The Trick
To avoid the component immediately rendering the center card, I instead render the card passed into the component immediately in its left and right cards that are initially hidden, leaving the center card blank (or whatever it was before). This means that the component should render the center card using the model stored in a useRef value which starts out being undefined.
Then, in a useEffect, call a function that adds a slide CSS class to the left (or right, depending on the direction I want to slide) card. This should kick off the translation animation. At the same time, start a timer (just like the raw JS example) matching the animation duration to:
- update the
useRef.currentto now point to the card passed in. - remove the slide CSS class so that the cards snap back into place.
- trigger a refresh so that the center card gets rendered using the updated
useRef.current(which should now be the card passed into the carousel).
app/models.ts
export type Card = {
...
title: string
copy: string
...
}
....app/cards/ui/cardcarousel.module.css
.slide-left {
transition: transform 0.3s;
transform: translate(-600px)
}
.slide-right {
transition: transform 0.3s;
transform: translate(600px)
}app/cards/page.tsx
'use client'
...
import { renderCard } from "@/app/lib/ui/renderers";
import { Carousel, Direction } from "../ui/CardCarousel"
...
export default function Page() {
...
// Tracks which Card (index into an array) is being displayed and how it
// should slide into the view
const [cardDisplayState, dispatch] = useReducer(
cardDisplayStateReducer, {index: 0, slideDirection: Direction.LEFT}
)
...
const { cards } = stack
return (
<div className="...">
...
<Carousel
t={cards[cardDisplayState.index]}
slideDirection={cardDisplayState.slideDirection}
renderer={renderCard}
/>
<Scroller ... />
</div>
)
}app/cards/ui/CardCarousel.tsx
import styles from "@/app/cards/ui/cardcarousel.module.css"
...
export enum Direction {
LEFT,
RIGHT
}
const SLIDE_CSS_CLASSNAME: Record<Direction, string> = {
[Direction.LEFT]: "slide-left",
[Direction.RIGHT]: "slide-right"
}
/**
* Parameters to the Carousel component.
*
* @param t the item model being rendered into a "card" to be displayed
* @param slideDirection the direction the new card will slide in to replace the center card
* @param renderer a function that will render the card for the item model
*/
type Parameters<T> = {
t?: T
slideDirection: Direction
renderer: (c: T|undefined) => JSX.Element
}
export function Carousel<T>({ t, slideDirection, renderer }: Parameters<T>) {
const currentTRef = useRef<T|undefined>(undefined)
// This is just to allow us to force an update (got this trick from a search)
const [, updateState] = useState<{}>();
const forceUpdate = useCallback(() => updateState({}), []);
const slideWithCssClassName = useCallback((slideCssClassName: string) => {
const elems = Array.from(document.getElementsByClassName("card"))
// Adding the class will trigger the animation
elems.forEach(elem => {
elem.classList.add(styles[slideCssClassName])
})
// Set up a timer to reset the elems (hopefully immediately after the animation completes)
setTimeout(() => {
// By this time, the slide animation should be complete. We can snap the elems back
// to the original positions by removing the class.
// currentTRef is not sync'ed, so this should not trigger a refresh on its own. We
// don't want it to in order to not interfere with the slide.
currentTRef.current = t
elems.forEach((elem) => {
elem.classList.remove(styles[slideCssClassName])
})
// Since currentTRef is not sync'ed, force an update manually now.
forceUpdate()
}, 300)
}, [t, currentTRef.current])
useEffect(
() => {
setTimeout(
() => slideWithCssClassName(SLIDE_CSS_CLASSNAME[slideDirection]),
150
)
},
[t, slideDirection]
)
// Truncated most of the Tailwind CSS classes for brevity
return (
<div className="...">
<div className="...">
<div className="card ... left-[-600px]" id="previous-card">
{renderer(t)}
</div>
<div className="card ..." id="current-card">
{renderer(currentTRef.current)}
</div>
<div className="card ... left-[600px] " id="next-card">
{renderer(t)}
</div>
</div>
</div>
)app/lib/ui/renderers.tsx
export function renderCard(card: Card|undefined): JSX.Element {
// Nothing special; just render the title and copy of the card
const cardDisplay = card ? (
<div className="...">
<div className="flex-none font-bold">{card!.title}</div>
<div className="grow">{card.copy}</div>
</div>
) : (
<></>
)
return <div className="size-full">{cardDisplay}</div>
}renderer === Card component?
That renderCard function in renders.tsx looks like just a Card component. Why not just write the component and call it from Carousel?
export function Carousel({ t, slideDirection }: Parameters<T>) {
const currentTRef = useRef<Card|undefined>(undefined)
...
// Truncated most of the Tailwind CSS classes for brevity
return (
<div className="...">
<div className="...">
<div className="card ... left-[-600px]" id="previous-card">
<Card card={t} ... />
</div>
<div className="card ..." id="current-card">
<Card card={currentTRef.current} />
</div>
<div className="card ... left-[600px] " id="next-card">
<Card card={t} ... />
</div>
</div>
</div>
)That’s what I started with. However, doing this will couple the Carousel component to the Card. I thought I’d try to have the Carousel be more reusable for other models/components.
The result is that a Carousel<T> that is bound to a model T and accepts a renderer function that knows how to render a “card” for that T. The Carousel<T> will just delegate the rendering of T to that renderer when needed.
So far I don’t know if there is a better way to accomplish that decoupling. An obvious approach is to have Carousel<T> accept a children as other composite components do. However, I think in that case children would be the rendered “current” card, and there is no way to hold on to the “previous” card without pushing up the logic of maintaining a “previous” vs. “current” card to the parent of the Carousel, and that seems to me like a leakage of the implementation concerns of the Carousel to its parent.
For now, therefore, the Carousel<T> will require a function that renders a “card” for the T. That function will be called with either the current or previous T depending on where in the flow the Carousel is.
And as can be seen with the Page.tsx, the parent (Page.tsx in this case) doesn’t need to worry about which is the previous Card and which is the current (or current vs. next) Card; the parent just passes the T (in this case Card) it wants to slide in, and the Carousel<T> component takes care of maintaining that previous/current state. The cost is that the parent does need to pass in a rendering function for the Card / T.
Do I get points taken off for using a rendering function instead of a “component”? 🤔
Result
I’ve increased the dimensions of the card (from 200×100 in Part 1) to 600×350. Again, I have skipped the whole Scroller component above since there’s nothing special there. However, it’s displaying those two chevrons at the bottom used to scroll between 3 cards.